User roles
- ACCOUNTADMIN – top level, should be granted to minimal number of users
- ORGADMIN – to be used with specific customer accounts
- SYSADMIN – create warehouses/databases/etc.; grant privileges on warehouses/databases/etc. Default role on first login.
- PUBLIC – automatically granted to every user/role
- SECURITYADMIN – monitor/manage users and roles
- USERADMIN – create users/roles
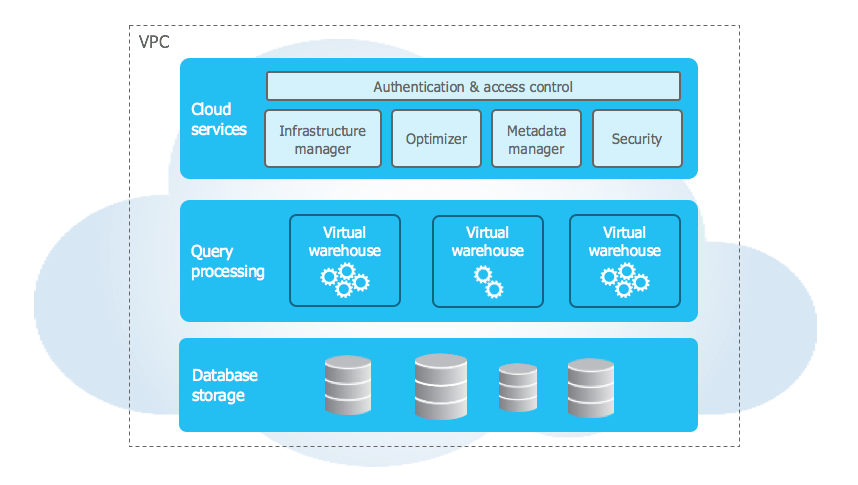
Architecture
- Cloud services – independent scalable services; brain of the system; monitors and optimizes tasks
- Query processing – Virtual warehouse; performs massive parallel processing; automatically scales; muscle of the system
- Database storage – hybrid columnar storage
Virtual Warehouse – Scaling Policies
- Standard – minimize queueing by starting additional clusters. Will shut down new clusters after 2-3 consecutive checks determining the load on least-busy cluster can be redistributed to existing clusters
- Economy – favors saving credits over starting additional clusters. Might result in query queuing. Will start a new cluster only if its estimated busy time >= 6 min. Will shut down new clusters after 5-6 consecutive checks
- https://www.snowflake.com/pricing/pricing-guide/
- Compute and Storage costs are separated. Billing is based on credits
- Credits<->$ rate depends on Snowflake edition use.
- Editions: Standard, Enterprise, Business Critical, Virtual Private. Free Trial account provides $400 worth of credits: https://docs.snowflake.com/en/user-guide/intro-editions.html
- See latest Credit balance under “Account” with ACCOUNTADMIN role
- Storage:
- On-demand – flat per TB charge with a minimum of approx. $23-$40. Varies per region.
- Pre-purchased - requires $ commitment per month, approx. $23 minimum
- See Pricing guide for exact numbers
- Virtual Warehouse / Compute:
- Sizes: from X-SMALL to 4X-LARGE. The large the size - the faster the query runs
- Sleep mode – consume no credits
- Billed by second, one min minimum
- Prices can vary per cloud provider/region/Snowflake edition
- Cloud Services:
- Typical level of utilization (up to 10% of daily credits) is free
- Data Transfer:
- Charges apply for data move between regions or cloud providers
- Data import (ex: external lake) may incur a charge
Cost optimization
- Choose Region wisely to minimize latency
- If need to move to another region – beware of data of transfer charges
- Use ‘Auto Suspension’ and ‘Auto Resume’ on clusters
- Monitor cost on account/warehouse/table level to prevent overspend
- Store data compressed
- Store data/timestamp columns as such and not as varchar
- Use transient tables where possible (be aware of only 1 day of time travel and no fail safe)
Resource monitors
- Can be set by account admin to control the credit spend
- Can trigger alert notifications
- Properties
- Credit quota – set on specific frequency/interval
- Schedule – frequency (at which to reset the limit), stat time, end time
- Monitor level – check credits for entire account or a specific warehouse; if not set – spend is not monitored
- Actions / triggers
- Notify & Suspend – send notification and suspend after all statements are run
- Notify & Suspend Immediately – send notification and suspend cancelling all running statements
- Notify - send notification, perform no other action
- Suspending w/house takes some time – even when suspending immediately
- Once a w/house is suspended by a monitor – remains suspended until either:
- Next period start
- Credit quota is increased
- Suspend threshold is increased
- W/house is no longer assigned to the monitor
- Monitor is dropped
- Create a monitor via console:

- Create monitor via code:
use role accountadmin;
create or replace resource monitor warehouseMonitor with credit_quota=25
triggers on 60 percent do notify
on 80 percent do notify
on 100 percent do suspend
on 120 percent do suspend_immediate;
- Associate the monitor with a warehouse:
alter warehouse compute_wh set resource_monitor = warehouseMonitor;
- Create and associate an account-level the monitor:
create resource monitor accountMonitor with credit_quota=1000
triggers on 100 percent do suspend;
alter account set resource_monitor = accountMonitor;
- IMPORTANT: a single motor can be assigned to multiple w/houses. A w/house can have only one monitor.
- Notifications / Monitors
- Set via

- Choices are: Web, Email, All, None
- https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions.html#
- Splitting up large tables into independent chunks
- Pros: Improves scalability and performance
- Cons: maintenance overhead, data skewness, patriots can grow disproportionally
- Micro-partitions in Snowflake – columnar, 50MB to 500MB of uncompressed data
- Columnar storage:
- Rows divided equally among micro-partitions
- Data is sorted and stored by column
- Cloud Services layer contains metadata on each partition – range of values, number of distinct, properties used for efficient querying, etc.
- Micro-partitions are created automatically by Snowflake, up to 500MB each in size (before compression)
- Values in multiple partitions can overlap – to prevent skewness
- Columns are compressed individually – Snowflake picks most appropriate algorithm for each case
- Data is written into partitions as and when it is inserted into the table
- Done to sort/order data to optimize retrieval
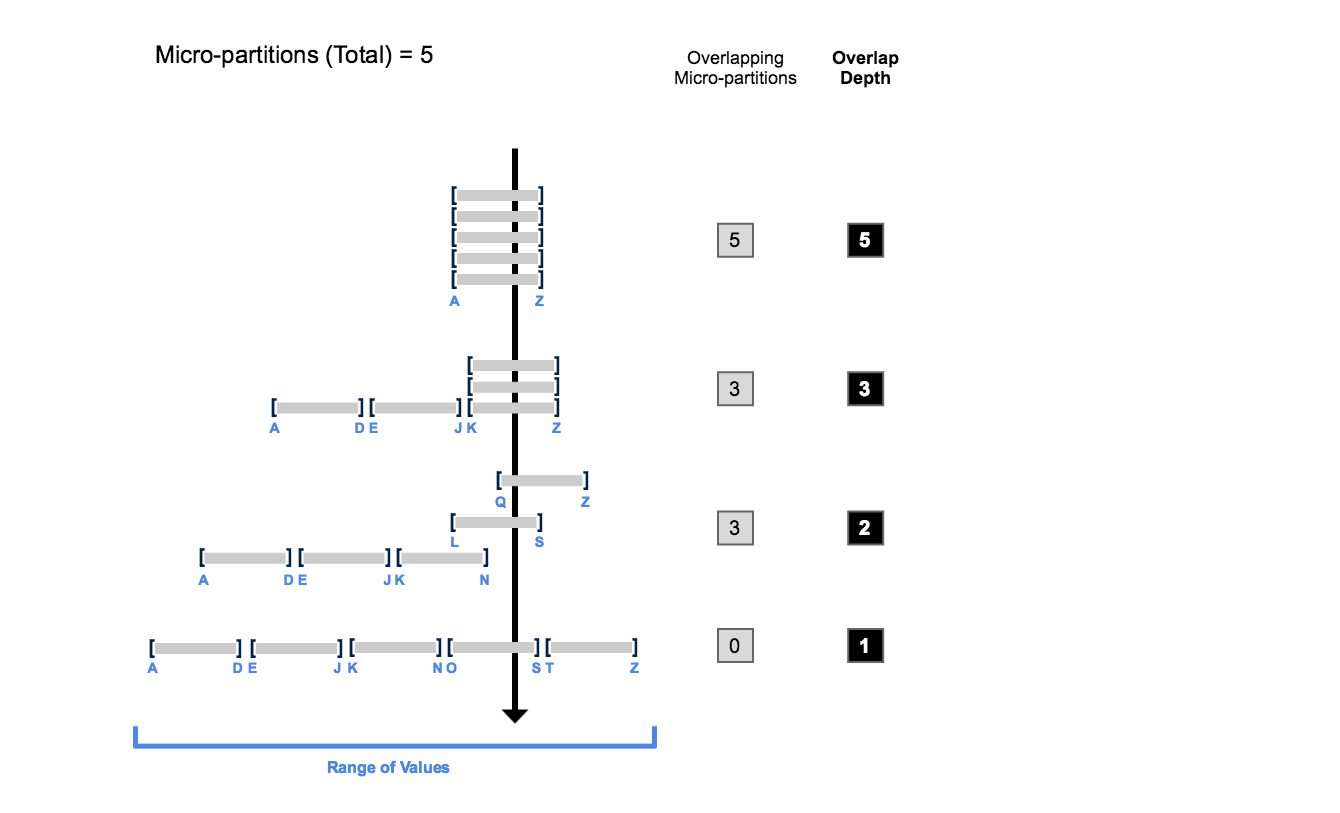
- Cluster contains metadata for each underlying partition – done to avoid extra scanning of each micro-partition at query time:
- Number of partitions that comprise a table
- Number of partitions tar extracted form dhat contain overlapping data
- Depth of overlapping micro-partitions
- Clustering depth:
- measure of clustering health, smaller = better
- no micro-partitions = depth of 0
- best for measuring query performance
- https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions.html
- Clustering key:
- subset of columns in a table OR expressions on a table (ex: year extracted from date)
- used when querying large tables
- OR when data overlapping among partitions is large
- Clustering can be computationally expensive
- Re-clustering is automatic – re-org the data to move related data physically closer to improve performance; consumes credits; can be explicitly disabled

- 14 days of history is available for viewing
- Can download previous 24 hours of result sets
- Can view queries of others on same account but not results
- Fast – will fetch row count form metadata
select count(*) from "SNOWFLAKE_SAMPLE_DATA"."TPCDS_SF100TCL"."CALL_CENTER";
- Slower – will fetch the actual data from data store
select * from "SNOWFLAKE_SAMPLE_DATA"."TPCDS_SF100TCL"."CALL_CENTER";
- Results get cached; subsequent queries will be faster

- Hint – if Size column under History is populated, means data was fetched from storage
- From worksheet's results area
- Copy - TSV format
- Download – TSV, CSV formats
- https://docs.snowflake.com/en/user-guide/querying-persisted-results.html
- Saves cost, speeds up performance.
- Metadata cache – holds object info, stats; never dropped
- Results – query results; stores for up to 24 hrs
- Warehouse cache – holds data locally as long as w/house is running
- Viewable under History
- Can not view other user’s cached data, but queries for one user can re-use cached results from other users
- Can re-use to optimize retravel is certain conditions are met – see link above
- Can query from the cache:
select * from "SNOWFLAKE_SAMPLE_DATA"."TPCDS_SF100TCL"."CATALOG_PAGE";
select cp_Department, cp_catalog_page_id,
cp_start_date_sk, cp_end_date_sk, cp_Description
from
table(result_scan(last_query_id()))
where cp_catalog_page_sk < 6;
- https://docs.snowflake.com/en/user-guide/data-load-snowpipe-intro.html#data-duplication
- Serverless data load mechanism
- Enables loading data from files as soon as they’re available in a stage
- Primarily used when data is generated frequently and in small volumes
- Leverages event notifications (ex: AWS SNS) for cloud storage to inform Snowpipe of the arrival of new data files to load. A dedicated COPY statement identifies the source location of the data files (i.e., a stage) and a target table. The user is billed for the compute each load consumes.
- Snowflake on AWS - load data from S3
- Objects and types:
- https://community.snowflake.com/s/article/Different-Types-of-Objects-in-Snowflake
- Objects: Database / Schema / Stage
- Database - logical grouping of schemas. Each database belongs to a single Snowflake account.
- Schema - logical grouping of database objects (tables, views, etc.). Each schema belongs to a single database.
- Namespace = Database + Schema
- Object types: Permanent / Temporary / Transient
- Tables:
- https://docs.snowflake.com/en/user-guide/tables-temp-transient.html
- Permanent
- default table type - created for longer term storage
- feature data propitiation and recovery mechanisms
- greater number of retention days as compared to temp / transient tables
- fail-safe period of 7 days
- time travel can be up to 90 days (on Enterprise Edition only)
- note that no specific keyword (e.g., PERMANENT) is needed to create a table
CREATE OR REPLACE DATABASE PERM_EXAMPLE;
- Temporary
- used for non-permanent data
- exists/persist only w/in the session - data is purged at session end
- non-visible to other users
- do not support cloning
- can have temp and non-temp tables with the same name within single schema. Temp table take precedence
create or replace TEMPORARY table EXAMPLE_TABLE_TEMP(custom_id number,
custom_field_1 date,
custom_field_2 varchar(10),
custom_field_3 number,
custom_field_ number);
- Transient
- persist until dropped
- very similar to permanent tables - but feature no fail-safe period
- used for data that does not require same level pf persistence/protection as in permanent tables
- contribute to the overall storage billing
- can have transient / database / schema / table. If a db is defined is transient - all schemas/tables are transient as well
- data retention (travel) - up to 1 day (both Standard and Enterprise editions)
CREATE OR REPLACE TRANSIENT DATABASE TRASN_EXAMPLE;
SHOW DATABASES;
DESC DATABASE TRASN_EXAMPLE;
USE DATABASE TRASN_EXAMPLE;
- Cloning
- To change a table type, create a CLONE of an existing table and DROP the original
- https://docs.snowflake.com/en/sql-reference/sql/create-clone.html
- Can only clone permanent and transient tables; temporary tables cannot be cloned
CREATE OR REPLACE transient TABLE TRASN_EXAMPLE
CLONE PERM_EXAMPLE;
DROP TABLE PERM_EXAMPLE;
- Can use COPY GRANTS to inherits any explicit access privileges granted on the original table but not inherit any future grants defined for the object type in the schema
- If COPY GRANTS isn't specified, then the new object clone does not inherit any privileges granted on the object; inherits any future grants
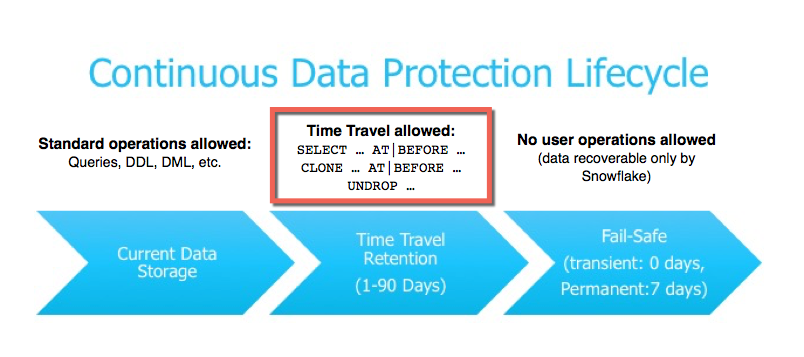
- https://docs.snowflake.com/en/user-guide/data-time-travel.html
- Set Retention Period property to enable
- Standard Edition - 1 day of travel (automatically enabled); can be set to 0; on account and object levels
- Enterprise - up to 90 days; for transient / permanent - default 1 day, but can reset to 0; for permanent - can be set to 0-90
create or replace table my_awesome_table(custom_id number,
custom_field_1 number,
custom_field_2 number)
data_retention_time_in_days=90;
alter table my_awesome_table set data_retention_time_in_days=30;
- Can set Retention Period higher up on the account or the database level. Changes to it would apply to all underlying objects unless explicitly set
- Fail-Safe zone - internal Snowflake backup not accessible to end user; used to ensure data persistence
- If need to extract from Fail-Safe (rare occasion) - need to contact Snowflake directly
- Time travel allows:
- query data that has been updated/deleted
- clone entire tables/schemas/dbs from at or before the specific points in the past
- restore dropped objects
- Once travel period has elapsed - data is moved into Fail-Safe
- https://docs.snowflake.com/en/user-guide/data-failsafe.html
- Querying the history
- Query for data as of a specific time
select * from my_awesome_table before(timestamp => '2021-10-24 20:50:28.944 +0000'::timestamp);
- Query for data as of 20 min ago
select * from my_awesome_table at(offset => -60*20);
- Query for data up to but not including changes made by the specified statement (see how to obtain statement id below)
select * from my_awesome_table before(statement => '<insert statement id here>');

- Restoring from history
- Restore into a new table data as-of-time from the original table
create table my_restored_table clone my_original_table at(timestamp => '2021-10-24 20:50:28.944 +0000'::timestamp);
- Create a restore of a schema as of 20 min ago
create schema restored_schema clone original_schema at(offset => -60*20);
- Restore a database to a state prior to execution of a particular statement
create database restored_db clone original_db before(statement => '<insert statement id here>');
- Restoring dropped data
- Dropped data isn't immediately removed. It is kept recoverable for the length of the retention period and subsequently moved into Fail-safe. Recover from Fail-safe isn't available to the end user. Can use show <object type e.g. table> history to see recoverable tables (see DROPPED_ON column on console)
drop table my_db.my_schema.my_awesome_table ;
show tables history like '%awesome%' in my_db.my_schema;
undrop table my_db.my_schema.my_awesome_table ;
- Undrop will fail of an object with the same name exists
- https://docs.snowflake.com/en/user-guide/data-failsafe.html
- Data can only be recovered by Snowflake. Ex: h/ware failure, AZ or Region outage
- It aims to minimize the downside of traditionally backup approach:
- time required to load data
- business downtime during recovery
- loss of data since last backup
- Begins where Time Travel ends
- Transient - 0 days; Permanent - 7 days
- Full database snapshots are sent to Fail Safe - need to be careful to control costs
- Best practice - use transient tables for non-prod to minimize expenditure
- To check Fail Safe storage used - see Account->Average Storage Used->Fail Safe. Need to be logged in as ACCOUNTADMIN or SECURITYADMIN
- https://docs.snowflake.com/en/user-guide/tasks-intro.html
- Execution of a single line of SQL
- Can not be triggered off an event - can be timed or scheduled
- Only a single instance of a task can be run at a time
No comments:
Post a Comment