- https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html
- A fully managed relational database engine that's compatible with MySQL and PostgreSQL
-
Uses same tools scripts etc. as MySQL and PostgreSQL
- Can take a snapshot of MySQL / PostgreSQL and restore onto Aurora
- Up to 5 times throughput of MySQL, 3 times of PostgreSQL w/out changes to existing apps
- Storage scales up to 64 TiB
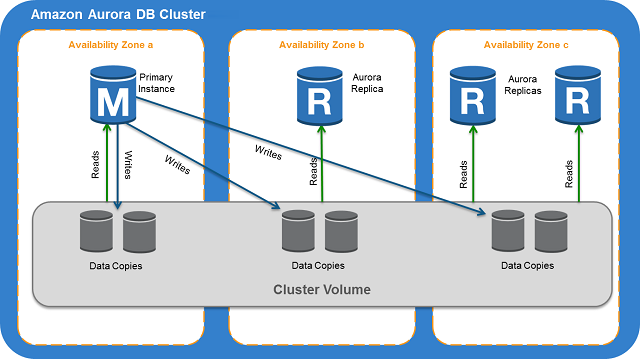
- One or more DB instance + a cluster to manage the data
- Cluster – multi-AZ, each AZ - 2 copies of data
- Separate compute capacity and data: Primary + Read Replicas; no Standby
- Can run with just the Primary and no Replicas
- Can have up to 15 replicas in a cluster
- Can failover to a Replica in case Primary fails
- Replicas can offload reads from Primary
- Data stored on SDD
- Two copies of data in each Cluster Volume
- Cluster volume can grow up to 65 TiB
- Data available for read on cluster <100 millisec after write on primary
- You are charged for max achieved storage only. Use 2 TiB – pay for 2, go down to 1, still paying for 2.
- Can have Aurora stored procedure invoke a Lambda function
- Can have Aurora read data from S3 and save as files into S3
- Automatic backups – continuous and incremental
- Backtrack – can rewind cluster to specific point in time up to 72 hours back. Chargeable. Backtrack lets you quickly recover from a user error. For example, if you accidentally deleted an important record at 10am, you could use Backtrack to move the Aurora database back to its state at 9:59am, before the error.
- Can take a snapshot of MySQL / PostgreSQL and restore onto Aurora
- Up to 5 times throughput of MySQL, 3 times of PostgreSQL w/out changes to existing apps
- Storage scales up to 64 TiB
- One or more DB instance + a cluster to manage the data
- Cluster – multi-AZ, each AZ - 2 copies of data
- Separate compute capacity and data: Primary + Read Replicas; no Standby
- Can run with just the Primary and no Replicas
- Can have up to 15 replicas in a cluster
- Can failover to a Replica in case Primary fails
- Replicas can offload reads from Primary
- Data stored on SDD
- Two copies of data in each Cluster Volume
- Cluster volume can grow up to 65 TiB
- Data available for read on cluster <100 millisec after write on primary
- You are charged for max achieved storage only. Use 2 TiB – pay for 2, go down to 1, still paying for 2.
- Can have Aurora stored procedure invoke a Lambda function
- Can have Aurora read data from S3 and save as files into S3
- Automatic backups – continuous and incremental
- Backtrack – can rewind cluster to specific point in time up to 72 hours back. Chargeable. Backtrack lets you quickly recover from a user error. For example, if you accidentally deleted an important record at 10am, you could use Backtrack to move the Aurora database back to its state at 9:59am, before the error.
Endpoint
- URL with host address/port. This allows for:
- Cluster endpoint
§ Connect to the current primary
§ Do all your cluster / db set up
§ Can't be changed, deleted or altered
§ Automatic seamless failover – min interruption of service
§ Only one reader end point exists
§ Aurora will load-balance across replicas for faster reading
§ Can't be used for writes, can’t delete / modify
§ If no Replicas – reader endpoint will read off Primary
§ Each instance has its own personal endpoint
§ Ex: if custom load-balancing is needed – can connect directly to instances
§ associate w subset of DB instances
§ upon connection Aurora will load-balance and choose an instance in the set to connect to
§ can have up to 5 custom endpoints
§ Ex: custom cluster for large instances
- Up to 15 replicas in one region
- Multiple replicas – single logical volume
- Data returned from a replica - w/in 100 milliseconds from the time it was committed to primary
- Can be in another region
- Encryption yes/no same as source
- You can promote a read replica to become a standalone cluster (takes a few minutes)
- Can replicate into/from Amazon RDS MySQL or to/from an external MySQL instance
- Cross-region replication is done over the public connections, not endpoints – need public subnets, SecGr etc.
- Cross-regional Replicas
- Can have up to 5 cross-regional clusters that are Read Replicas
- Can promote one of the replicas to be a standalone – a reboot of all DB instance will happen, takes a few mins
- Good as DR mechanism
- https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Integrating.AutoScaling.html
- Need to specify Min / Max number of replicas
- Scale up / down as per Cloud Watch metric behavior
- Need at least one replica for auto scaling to work
- Failover – a replica becomes the primary, endpoint is automatically repointed to the new primary; brief interruption in r/w to the primary – txn’t fail with exception. If no replica exists – need to launch, takes time.
- Recommendation – have replicas of same instance class (X-Large, etc.) ready in an AZ away from primary
- SLL for in-transit from client
- At rest: DB encryption on primary and replicas, AES-256
- Can’t convert an unencrypted cluster into encrypted, can’t turn off encryption:
§ Can restore an unencrypted snapshot into an encrypted volume
- Data in-transit from Primary to Replicas is encrypted, even across regions
- Another region copy of the entire cluster, read-only, latency advantage
- Can have up to 16 replicas, since no master
- Replication latency from mater usually under a second
- Restore from snapshot into a Global Cluster
- Can be used to failover from current primary into another region
- Continuous and incremental. Can restore to any point in time within backup retention period – into a new cluster
- Backups stored 1-35 days
- Can take snapshot to keep a copy beyond retention period
- Manual snapshot can be shared, encrypted or not
- Can restore a cluster from a snapshot
- To share an automated snapshot - create a manual copy
- Can share a manual snapshot with up to 20 accounts
- Unencrypted can be made public for everyone
- Encrypted at rest – can be shared by sharing the key
Backtrack – can rewind the cluster to specific time. Different from
backup/restore. Can roll back and then forward in time to undo mistakes
Failover
-
Failover is automatically
handled by Amazon Aurora so that your applications can resume database
operations as quickly as possible without manual administrative intervention- If you have an Amazon Aurora Replica in the same or a different Availability Zone, when failing over, Amazon Aurora flips the canonical name record (CNAME) for your DB Instance to point at the healthy replica, which in turn is promoted to become the new primary. Start-to-finish, failover typically completes within 30 seconds.
- If you are running Aurora Serverless and the DB instance or AZ become unavailable, Aurora will automatically recreate the DB instance in a different AZ
-
If you do not have an Amazon
Aurora Replica (i.e. single instance) and are not running Aurora Serverless,
Aurora will attempt to create a new DB Instance in the same Availability Zone
as the original instance. This replacement of the original instance is done on
a best-effort basis and may not succeed, for example, if there is an issue that
is broadly affecting the Availability Zone
No comments:
Post a Comment